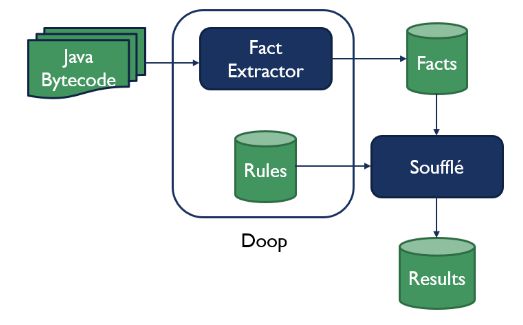
--android Force Android mode for code inputs that are not in .apk format. --app-only Only analyze the application input(s), ignore libraries/platform. --cfg Perform a CFG analysis. --dry-run Do a dry run of the analysis (generate facts and compile but don't run analysis logic). --extra-logic <FILE> Include files with extra rules. --gen-opt-directives Generate additional relations for code optimization uses.
-h,--help <SECTION> Display help and exit. Valid values: all, configuration, data-flow, datalog-engine, entry-points, fact-generation, heap-snapshots, information-flow, native-code, open-programs, python, reflection, server-logic, statistics, xtras -i,--input-file <INPUT> The (application) input files of the analysis. Accepted formats: .jar, .war, .apk, .aar, maven-id --id <ID> The analysis id. If omitted, it is automatically generated. -L,--level <LOG_LEVEL> Set the log level: debug, info or error (default: info). -l,--library-file <LIBRARY> The dependency/library files of the application. Accepted formats: .jar, .apk, .aar --max-memory <MEMORY_SIZE> The maximum memory that the analysis can consume (does not include memory needed by fact generation). Example values: 2m, 4g. --platform <PLATFORM> The platform on which to perform the analysis. For Android, the plaftorm suffix can either be 'stubs' (provided by the Android SDK), 'fulljars' (a custom Android build), or 'apks' (custom Dalvik equivalent). Default: java_8. Valid values: java_3, java_4, java_5, java_6, java_7, java_7_debug, java_8, java_8_debug, java_8_mini, java_9, java_10, java_11, java_12, java_13, java_14, java_15, java_16, android_22_fulljars, android_25_fulljars, android_2_stubs, android_3_stubs, android_4_stubs, android_5_stubs, android_6_stubs, android_7_stubs, android_8_stubs, android_9_stubs, android_10_stubs, android_11_stubs, android_12_stubs, android_13_stubs, android_14_stubs, android_15_stubs, android_16_stubs, android_17_stubs, android_18_stubs, android_19_stubs, android_20_stubs, android_21_stubs, android_22_stubs, android_23_stubs, android_24_stubs, android_25_stubs, android_26_stubs, android_27_stubs, android_28_stubs, android_29_stubs, android_25_apks, android_26_robolectric, python_2 -t,--timeout <TIMEOUT> The analysis execution timeoutin minutes (default: 90 minutes). -v,--version Display version and exit.
数据流分析相关选项,没有用过。
1 2
--data-flow-goto-lib Allow data-flow logic to go into library code using CHA. --data-flow-only-lib Run data-flow logic only for library code.
--souffle-jobs <NUMBER> Specify number of Souffle jobs to run (default: 4).
分析的入口点选择,没有用过,貌似不指定寻找 main 类就触发 open-program 分析。
1 2 3 4 5
--discover-main-methods Discover main() methods. --discover-tests Discover and treat test code (e.g. JUnit) as entry points. --exclude-implicitly-reachable-code Don't make any method implicitly reachable. --ignore-main-method If main class is not given explicitly, do not try to discover it from jar/filename info. Open-program analysis variant may be triggered in this case. --main <MAIN> Specify the main class(es) separated by spaces.
--also-resolve <CLASS> Force resolution of class(es) by Soot. --cache The analysis will use the cached facts, if they exist. --dont-cache-facts Don't cache generated facts. --extract-more-strings Extract more string constants from the input code (may degrade analysis performance). --fact-gen-cores <NUMBER> Number of cores to use for parallel fact generation. --facts-only Only generate facts and exit. --generate-jimple Generate Jimple/Shimple files along with .facts files. --input-id <ID> Import facts from dir with id ID and start the analysis. Application/library inputs are ignored. --report-phantoms Report phantom methods/types during fact generation. --thorough-fact-gen Attempt to resolve as many classes during fact generation (may take more time). --unique-facts Eliminate redundancy from .facts files. --wala-fact-gen Use WALA to generate the facts. --Xfacts-subset <SUBSET> Produce facts only for a subset of the given classes. Valid values: PLATFORM, APP, APP_N_DEPS --Xignore-factgen-errors Continue with analysis despite fact generation errors. --Xsymlink-input-facts Use symbolic links instead of copying cached facts. Used with --cache or --input-id.
--open-programs <STRATEGY> Create analysis entry points and environment using various strategies (such as 'concrete-types' or 'jackee'). --open-programs-context-insensitive-entrypoints --open-programs-heap-context-insensitive-entrypoints
--distinguish-reflection-only-string-constants Merge all string constants except those useful for reflection. --distinguish-string-buffers-per-package Merges string buffer objects only on a per-package basis (default behavior for reflection-classic). --light-reflection-glue Handle some shallow reflection patterns without full reflection support. --reflection Enable logic for handling Java reflection. --reflection-classic Enable (classic subset of) logic for handling Java reflection. --reflection-dynamic-proxies Enable handling of the Java dynamic proxy API. --reflection-high-soundness-mode Enable extra rules for more sound handling of reflection. --reflection-invent-unknown-objects --reflection-method-handles Reflection-based handling of the method handle APIs. --reflection-refined-objects --reflection-speculative-use-based-analysis --reflection-substring-analysis Allows reasoning on what substrings may yield reflection objects. --tamiflex <FILE> Use file with tamiflex data for reflection.
--stats none 可以用于关闭统计。
1
--stats <LEVEL> Set statistics collection logic. Valid values: none, default, full