Python 爬取 twitter 数据
前言
接到一个需求:爬包含关键字的推文。后来才告诉我转交给别人做了(摊手),那这里就分享一下如何爬取 twitter 数据。
结果我拖了两周才开始梳理 😂
Twitter API
推特提供了 Twitter API,可以用于查询推特数据,个人使用的话有以下两种:
- Twitter API v2
- Standard v1.1
当然还有高级版和企业版:
- Premium v1.1
- Enterprise
标准版仅支持搜索 7 天内的推特,其余都支持全搜索(从 2006.03 开始),官方给出了比较:Comparing Twitter API’s Search Tweets endpoints 。
使用标准版需要申请开发者账户Apply for a developer account,使用 v2 版本的需要申请 Academic Research product track。我试了申请开发者账户,然后妥妥地被拒绝了,有人说需要美国账户/手机号之类的信息,因为不想拿自用的推特瞎测试,也就罢了。
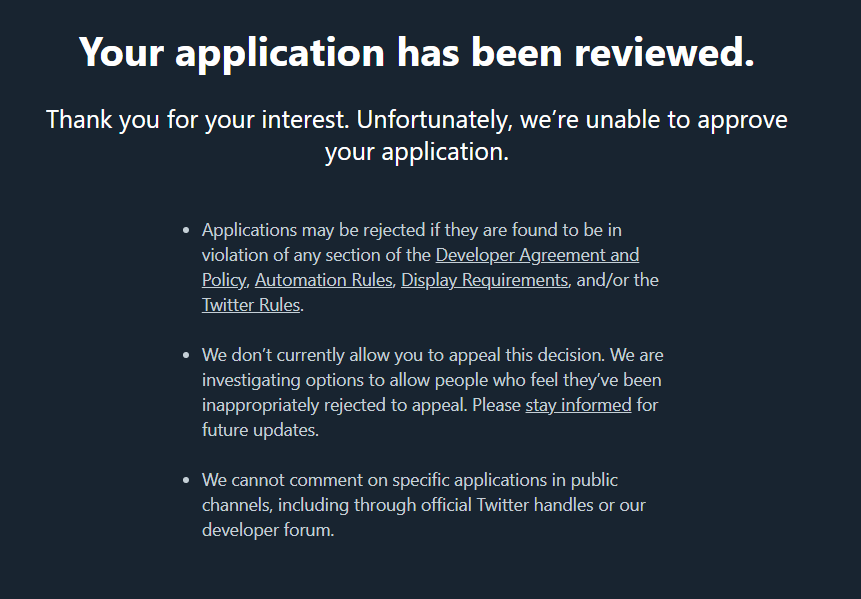
这里的目标是搜索特定时间范围内,包含特定关键词的 tweets(即,推文),因此就算申请到了也不能满足需求,转而寻求开源解决方案。
开源解决方案
搜索 GitHub 上爬取 twitter 数据的开源项目,筛选出以下 9 个试用(按 star 数量排列):
| 名称 | star | 最后一次更新 | 是否可用 |
|---|---|---|---|
| twint | 13k | 2021.03.03 | ❌ |
| tweepy | 8.7k | 2022.04.22 | ✔️(需要申请 Twitter API) |
| twitter-scraper | 3.2k | 2021.12.18 | ❌ |
| twitterscraper | 2k | 2020.07.28 | ❌ |
| Scweet | 383 | 2022.03.23 | ✔️ |
| SearchTT | 146 | 2020.06.04 | ❌ |
| Twitter Hashtag crawler | 75 | 2020.12.16 | ❌ |
| stweet | 99 | 2021.10.14 | ✔️ |
| Web_Scraping_Tweet_Traffic | 6 | 2019.12.15 | ❌ |
twint
不用 Twitter API 爬取推文,支持标签、趋势、敏感信息等搜索选项,也支持爬取用户信息,包括关注者、推文。
-
安装
直接从 pypi 安装的包版本较低,需要升级
1
pip install --upgrade git+https://github.com/twintproject/twint.git@origin/master#egg=twint
-
示例
配置一个代理
1
2
3
4
5
6
7
8
9
10
11
12
13
14import twint
c = twint.Config()
c.Proxy_host = '127.0.0.1'
c.Proxy_port = '7890'
c.Proxy_type = 'http'
c.Store_csv = True
c.Output = "tweets.csv"
c.Limit = 10
c.Custom_query = "nijisanji"
twint.run.Search(c)然后挂掉
1
WARNING:root:Error retrieving https://twitter.com/: ConnectTimeout(MaxRetryError("HTTPSConnectionPool(host='twitter.com', port=443): Max retries exceeded with url: / (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x000001D2C5A295B0>, 'Connection to twitter.com timed out. (connect timeout=10)'))")), retrying
翻了翻 issue 有人在二月份修复了:Fix the bug that proxy cannot be used when get token #1138,但没有合并。
顺便发现有人提设置时间范围的
since和until失效了 -
总结
自己试着修改或者等一个大更新,四百多的 issue 看来是没有太多的精力修啊😅
tweepy
实际上就是对 twitter API 的封装,不用从零手写请求和处理数据。
-
安装
1
pip install tweepy
-
示例
没有申请到开发者账户,跳过!
1
2
3
4
5
6
7
8
9
10import tweepy
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
public_tweets = api.home_timeline()
for tweet in public_tweets:
print(tweet.text) -
总结
Twitter API v2 的支持还在开发中,申请到开发者账户的就用它吧!
twitter-scraper
支持标签、趋势等搜索选项,也支持用户信息的搜索。
-
安装
1
pip install twitter_scraper
-
示例
因为没有提供设值代理的选项,所以直接在本地开全局模式代理
1
2
3
4from twitter_scraper import get_tweets
for tweet in get_tweets('twitter'):
print(tweet['text'])报错😅
1
requests.exceptions.ProxyError: HTTPSConnectionPool(host='twitter.com', port=443): Max retries exceeded with url: /i/profiles/show/twitter/timeline/tweets?include_available_features=1&include_entities=1&include_new_items_bar=true (Caused by ProxyError('Cannot connect to proxy.', OSError(0, 'Error')))
改下源码,报错在 tweets.py 这个文件,添加代理
1
2
3
4
5def get_tweets(query, pages=25):
def gen_tweets(pages):
proxy = 'http://127.0.0.1:7890'
r = session.get(url, headers=headers, proxies={'http': proxy, 'https': proxy})
...重新执行,新的报错😅
1
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
-
总结
作者说现在已经无法使用了(Does this work? #191),而且自己忙于工作暂时没时间更新(Doesn’t scrap anything. #189),暂且观望吧。
twitterscraper
所以为什么要起一样的名字?!
-
安装
1
pip install twitterscraper
-
示例
直接上命令行了,但是无法访问默认代理 https://free-proxy-list.net
1
twitterscraper Trump --limit 1000 --output=tweets.json
报错
1
requests.exceptions.ConnectionError: HTTPSConnectionPool(host='free-proxy-list.net', port=443): Max retries exceeded with url: / (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x0000019FAE33BDC0>: Failed to establish a new connection: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。'))
修改源码 query.py,直接返回本地代理
1
2
3
4
5
6
7
8
9
10
11
12def get_proxies():
return ['127.0.0.1:7890']
response = requests.get(PROXY_URL)
soup = BeautifulSoup(response.text, 'lxml')
table = soup.find('table',id='proxylisttable')
list_tr = table.find_all('tr')
list_td = [elem.find_all('td') for elem in list_tr]
list_td = list(filter(None, list_td))
list_ip = [elem[0].text for elem in list_td]
list_ports = [elem[1].text for elem in list_td]
list_proxies = [':'.join(elem) for elem in list(zip(list_ip, list_ports))]
return list_proxies输出请求参数,然后报错…
1
2
3
4
5
6
7
8
9
10
11
12INFO:twitterscraper:queries: ['Trump since:2006-03-21 until:2006-12-30', 'Trump since:2006-12-30 until:2007-10-10', 'Trump since:2007-10-10 until:2008-07-20', 'Trump since:2008-07-20 until:2009-04-30', 'Trump since:2009-04-30 until:2010-02-08', 'Trump since:2010-02-08 until:2010-11-19', 'Trump since:2010-11-19 until:2011-08-31', 'Trump since:2011-08-31 until:2012-06-10', 'Trump since:2012-06-10 until:2013-03-21', 'Trump since:2013-03-21 until:2013-12-30', 'Trump since:2013-12-30 until:2014-10-10', 'Trump since:2014-10-10 until:2015-07-21', 'Trump since:2015-07-21 until:2016-04-30', 'Trump since:2016-04-30 until:2017-02-09', 'Trump since:2017-02-09 until:2017-11-20', 'Trump since:2017-11-20 until:2018-08-31', 'Trump since:2018-08-31 until:2019-06-11', 'Trump since:2019-06-11 until:2020-03-21', 'Trump since:2020-03-21 until:2020-12-30', 'Trump since:2020-12-30 until:2021-10-11']
ConnectionError HTTPSConnectionPool(host='twitter.com', port=443): Max retries exceeded with url: /search?f=tweets&vertical=default&q=Trump%20since%3A2006-03-21%20until%3A2006-12-30&l=None (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x000002975B91D430>: Failed to establish a new connection: [WinError 10060] 由于连接方在一段时间
后没有正确答复或连接的主机没有反应,连接尝试失败。')) while requesting "https://twitter.com/search?f=tweets&vertical=defa
ult&q=Trump%20since%3A2006-03-21%20until%3A2006-12-30&l=None"
Traceback (most recent call last):
File "C:\Users\linki\Desktop\t\lib\site-packages\urllib3\connection.py", line 174, in _new_conn
conn = connection.create_connection(
File "C:\Users\linki\Desktop\t\lib\site-packages\urllib3\util\connection.py", line 96, in create_connection
raise err
File "C:\Users\linki\Desktop\t\lib\site-packages\urllib3\util\connection.py", line 86, in create_connection
sock.connect(sa)
TimeoutError: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。 -
总结
翻了翻 issue:没法用,等更新。
Scweet
支持关键词、标签、时间范围等搜索选项,也支持用户信息、关注、关注者的爬取。
-
安装
1
pip install Scweet==1.6
-
示例
用 selenium 模拟浏览器访问,竟然还不是 headless 模式,直接给我弹出一个窗口可还行。注意这里不是本地时间,是 UTC 时间;存储格式为 UTF-8。
1
2
3
4
5
6from Scweet.scweet import scrape
data = scrape(words=["nijisanji"], since="2020-01-01", until="2021-01-01", from_account=None,
interval=1,
headless=False, display_type="Latest", save_images=False, proxy="127.0.0.1:7890", save_dir='outputs',
resume=False, filter_replies=True, proximity=False)结果爬了 175 条数据
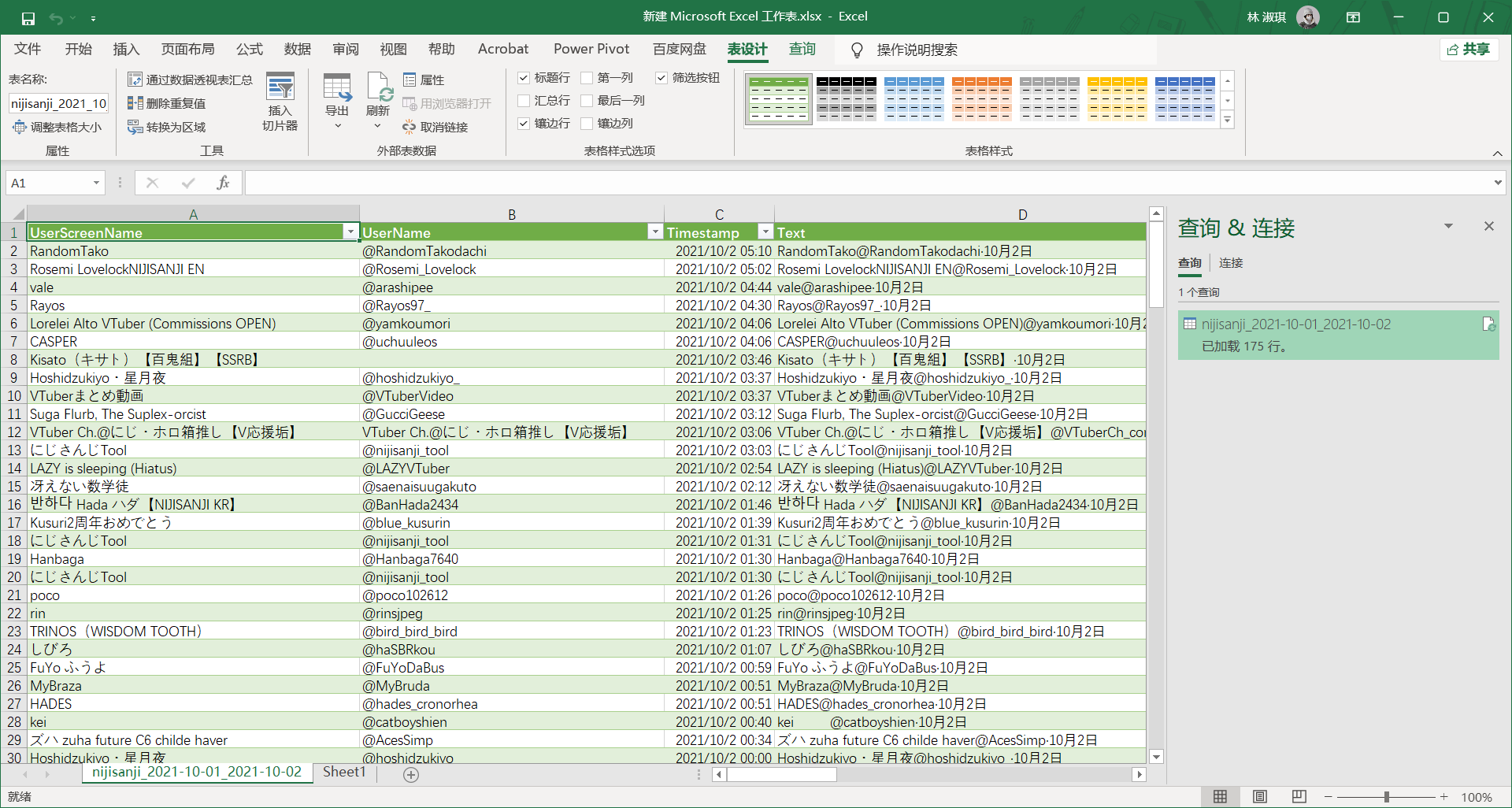
-
总结
可以用!暂时没遇到什么问题,用它!
SearchTT
还写了一篇知乎文章:这可能是是中文网上关于Twitter信息检索爬虫最全的项目了
描述含糊、仓库不更新、甚至还曾出租 API(评论里看起来可能是),拉倒🙃。
Twitter Hashtag crawler
根据标签(hashtag)搜索
-
安装
1
2
3git clone https://github.com/amitupreti/Hands-on-WebScraping
cd Hands-on-WebScraping/project1_twitter_hashtag_crawler
pip install -r requirements.txt报错
1
2ERROR: Could not find a version that satisfies the requirement dateutil (from versions: none)
ERROR: No matching distribution found for dateutil但是本地已经有了 dateutil
1
2
3
4pip install python-dateutil --upgrade
# Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
# Requirement already satisfied: python-dateutil in c:\users\linki\desktop\t\lib\site-packages (2.8.2)
# Requirement already satisfied: six>=1.5 in c:\users\linki\desktop\t\lib\site-packages (from python-dateutil) (1.16.0)直接装个 scrapy 得了
1
2pip install scrapy
pip install ipdb -
示例
没有给代理配置的入口,显然连不上
1
scrapy crawl twittercrawler -a filename=myhashtags.csv -o mydata.csv
-
总结
能够自定义的配置项太少,而且仅针对标签搜索,跳过。
stweet
支持推特的高级搜索选项,同时支持推文和用户信息的爬取~~,stweet/docs/notebooks/ 目录下有各种示例~~。
-
安装
1
pip install stweet
-
示例
提供许多配置项,非常友好
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23import arrow
import stweet as st
ProxyConfig = st.RequestsWebClientProxyConfig(
http_proxy="127.0.0.1:7890",
https_proxy="127.0.0.1:7890"
)
since = arrow.get('2021-10-01')
until = arrow.get('2021-10-02')
search_tweets_task = st.SearchTweetsTask(
exact_words="nijisanji",
since=since,
until=until,
replies_filter=st.RepliesFilter.ONLY_ORIGINAL,
)
st.TweetSearchRunner(
search_tweets_task=search_tweets_task,
tweet_outputs=[st.CsvTweetOutput('nijisanji_20211001_20211002.csv'), st.PrintTweetOutput()],
web_client=st.RequestsWebClient(proxy=ProxyConfig, verify=False),
).run()不碍事儿的警告
1
2C:\Users\linki\Desktop\t\lib\site-packages\urllib3\connectionpool.py:1013: InsecureRequestWarning: Unverified HTTPS request is being made to host '127.0.0.1'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
warnings.warn(添加以下语句关闭
1
2import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)爬得非常快,字段也比 scweet 收集的多,但是只有 2021.10.02 的数据,难道时间范围是左开右闭的。多试几次发现爬太快了提示
远程主机强迫关闭了一个现有的连接,而且每次爬取的结果都不一样…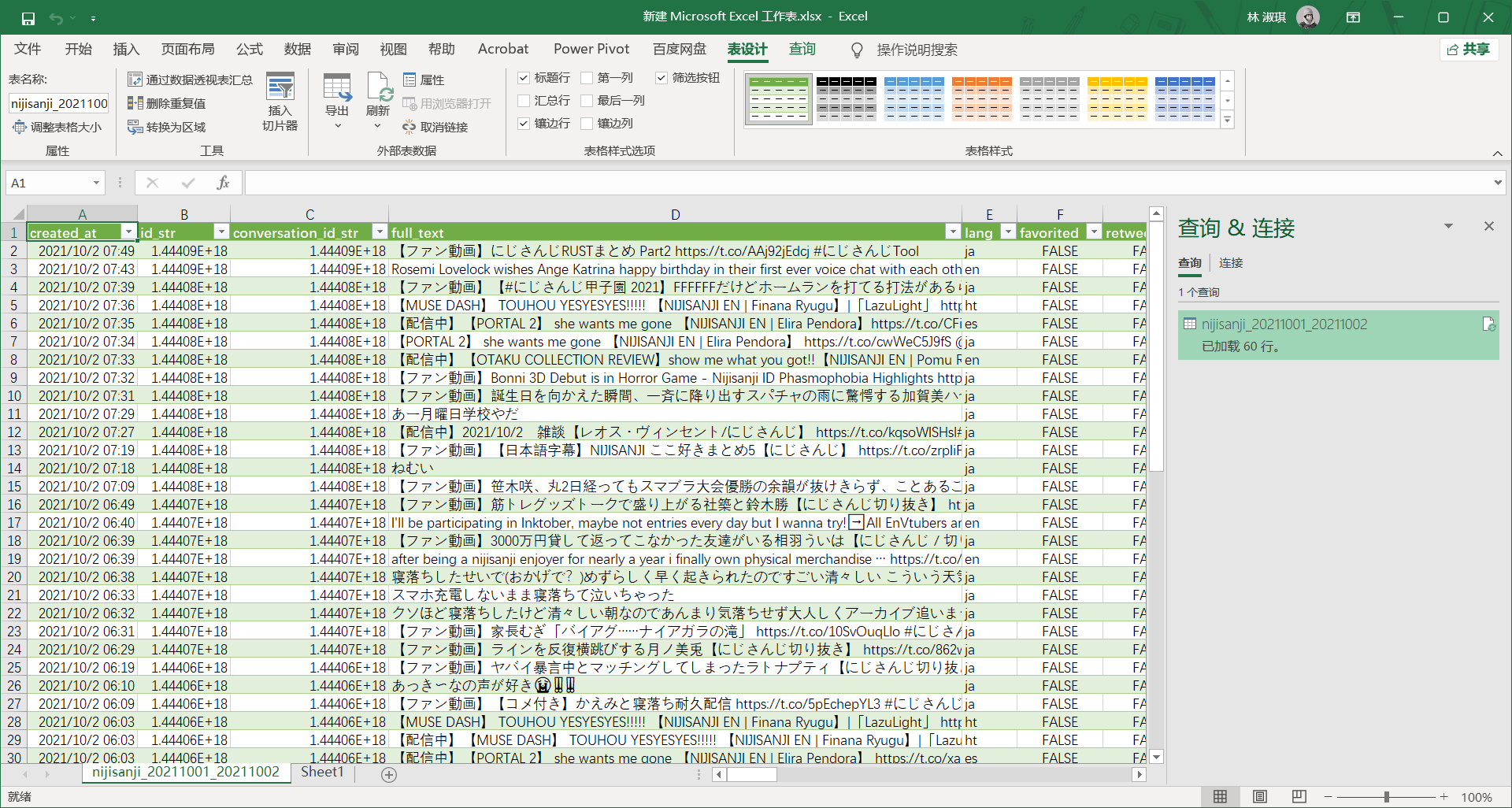
-
总结
虽然能用但有点问题,作者正在准备 stweet 2.0,等推出之后再进行尝试。
-
更新
2021.10.14 更新 stweet 2.0,说明文档还不够完善,如何使用的例子也没有。
2021.10.15 测试了一下,可以爬取推文数据和用户数据否,但是现在只支持保存 JSON 格式的文件(因为没写解析),重复爬取了几次从文件大小上看都一样,所以应该没问题了。可以再等等完善。
Web_Scraping_Tweet_Traffic
配合文章食用:
该仓库已于 2019 年停更,可作为爬取思路的学习材料。
在线爬取
https://www.vicinitas.io/free-tools/download-search-tweets ,需要推特账户登陆后爬取,可以一试。