1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
| import gradio as gr
import ollama
import time
import tiktoken
system_prompt = """
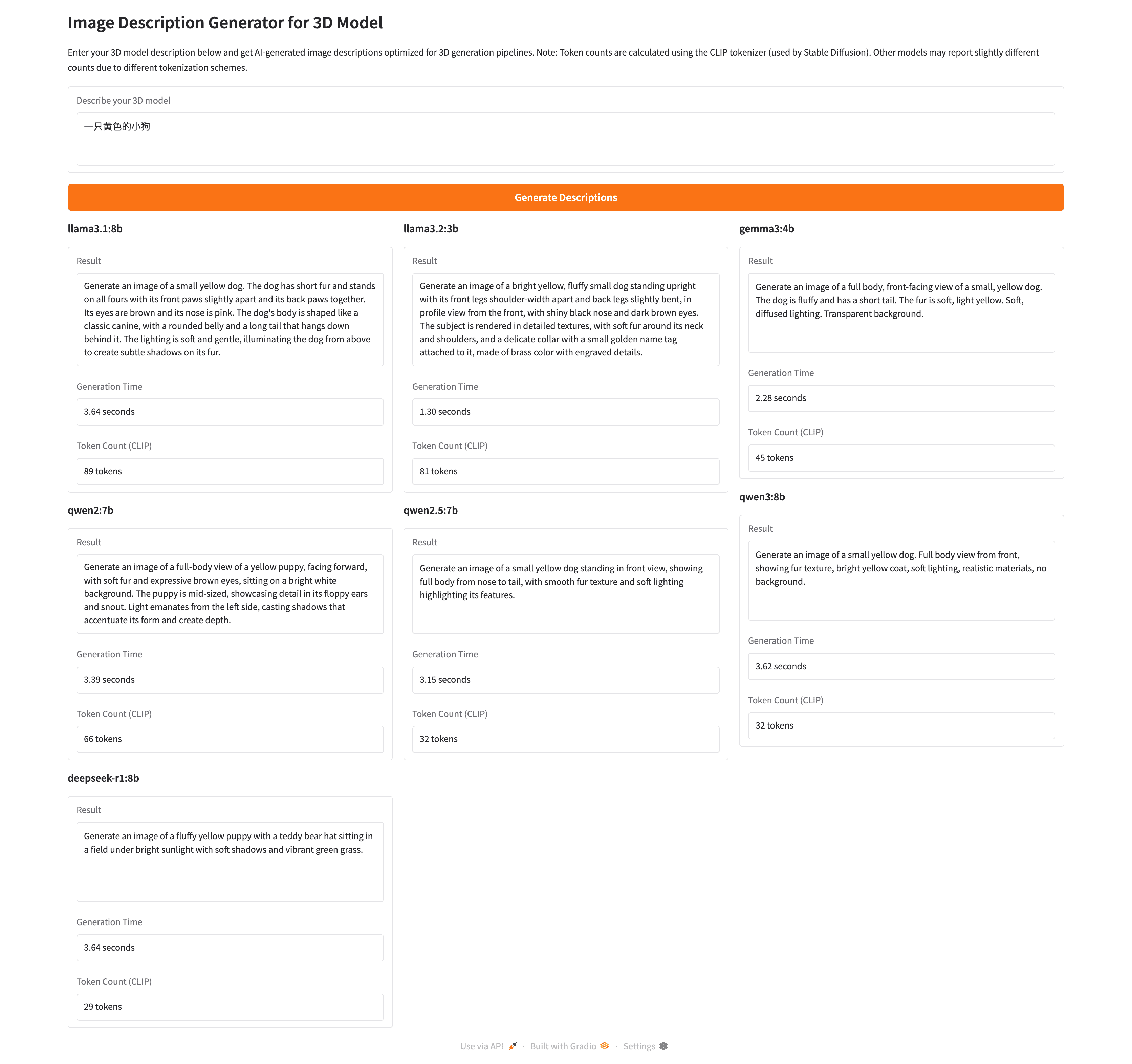
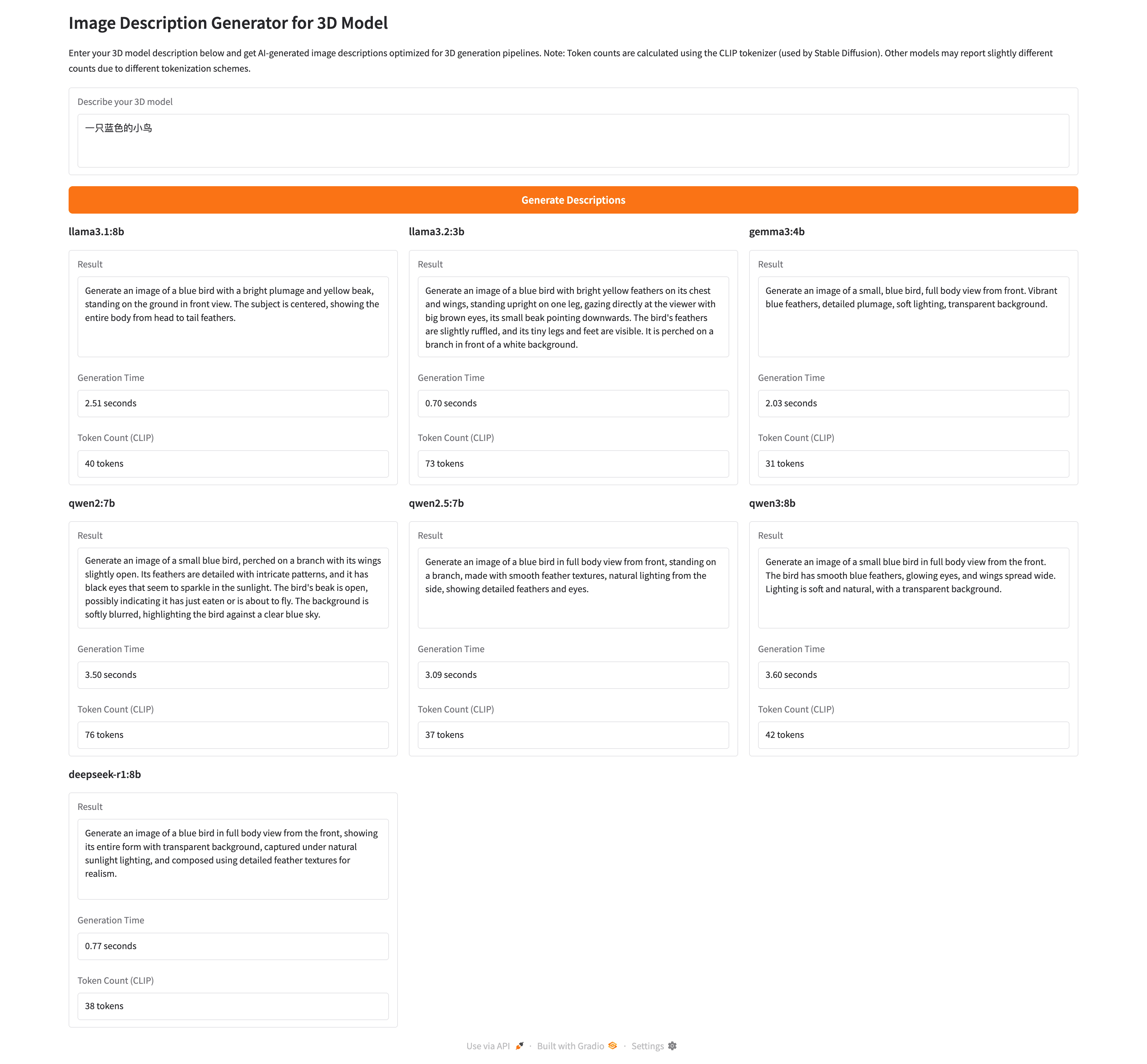
Generate a concise image description for 3D model generation. DO NOT ask for additional information or engage in dialogue - work with what is provided.
CRITICAL RULES:
1. MAX 75 TOKENS (CLIP tokenizer)
2. ENGLISH ONLY
3. NO BACKGROUND (transparent/white)
4. Full body view from front
5. Start with "Generate an image of..."
6. Generate the image description in ENGLISH ONLY, regardless of the input language. Do not mix languages in your response.
Include: subject, key details, materials, lighting, perspective. Be specific but concise. SHOW THE COMPLETE SUBJECT - no cropping, no cutoff body parts. For animals, show full body from nose to tail. For characters, show from head to toe.
"""
def generate_all_responses(user_input):
start_time = time.time()
model_ids = [
"llama3.1:8b",
"llama3.2:3b",
"gemma3:4b",
"qwen2:7b",
"qwen2.5:7b",
"qwen3:8b",
"deepseek-r1:8b",
]
responses = []
timings = []
token_counts = []
encoder = tiktoken.get_encoding("cl100k_base")
messages = [
{
"role": "system",
"content": system_prompt,
},
{
"role": "user",
"content": user_input,
},
]
for model_id in model_ids:
try:
response = ollama.chat(model=model_id, messages=messages, think=False)
final_output = response["message"]["content"]
responses.append(final_output.strip())
timings.append(f"{response.total_duration/1_000_000_000:.2f} seconds")
token_count = len(encoder.encode(final_output))
token_counts.append(f"{token_count} tokens")
print(f"{model_id}:{final_output.strip()}")
except Exception as e:
responses.append(f"Error with model {model_id}: {str(e)}")
timings.append("N/A")
token_counts.append("N/A")
total_elapsed_time = time.time() - start_time
print(f"User Prompt: {user_input}")
print(f"Total Processing Duration: {total_elapsed_time:.2f} seconds")
return tuple(responses + timings + token_counts)
with gr.Blocks(title="Image Description Generator for 3D Model") as demo:
gr.Markdown("# Image Description Generator for 3D Model")
gr.Markdown(
"Enter your 3D model description below and get AI-generated image descriptions optimized for 3D generation pipelines. Note: Token counts are calculated using the CLIP tokenizer (used by Stable Diffusion). Other models may report slightly different counts due to different tokenization schemes."
)
with gr.Row():
input_text = gr.Textbox(
label="Describe your 3D model",
placeholder="E.g., 'A futuristic cyberpunk drone with neon lights'",
lines=3,
)
with gr.Row():
submit_btn = gr.Button("Generate Descriptions", variant="primary")
with gr.Row():
with gr.Column():
gr.Markdown("### llama3.1:8b")
output1 = gr.Textbox(label="Result", lines=5, interactive=False)
timing1 = gr.Textbox(label="Generation Time", interactive=False)
tokens1 = gr.Textbox(label="Token Count (CLIP)", interactive=False)
gr.Markdown("### qwen2:7b")
output4 = gr.Textbox(label="Result", lines=5, interactive=False)
timing4 = gr.Textbox(label="Generation Time", interactive=False)
tokens4 = gr.Textbox(label="Token Count (CLIP)", interactive=False)
gr.Markdown("### deepseek-r1:8b")
output7 = gr.Textbox(label="Result", lines=5, interactive=False)
timing7 = gr.Textbox(label="Generation Time", interactive=False)
tokens7 = gr.Textbox(label="Token Count (CLIP)", interactive=False)
with gr.Column():
gr.Markdown("### llama3.2:3b")
output2 = gr.Textbox(label="Result", lines=5, interactive=False)
timing2 = gr.Textbox(label="Generation Time", interactive=False)
tokens2 = gr.Textbox(label="Token Count (CLIP)", interactive=False)
gr.Markdown("### qwen2.5:7b")
output5 = gr.Textbox(label="Result", lines=5, interactive=False)
timing5 = gr.Textbox(label="Generation Time", interactive=False)
tokens5 = gr.Textbox(label="Token Count (CLIP)", interactive=False)
with gr.Column():
gr.Markdown("### gemma3:4b")
output3 = gr.Textbox(label="Result", lines=5, interactive=False)
timing3 = gr.Textbox(label="Generation Time", interactive=False)
tokens3 = gr.Textbox(label="Token Count (CLIP)", interactive=False)
gr.Markdown("### qwen3:8b")
output6 = gr.Textbox(label="Result", lines=5, interactive=False)
timing6 = gr.Textbox(label="Generation Time", interactive=False)
tokens6 = gr.Textbox(label="Token Count (CLIP)", interactive=False)
submit_btn.click(
fn=generate_all_responses,
inputs=input_text,
outputs=[
output1,
output2,
output3,
output4,
output5,
output6,
output7,
timing1,
timing2,
timing3,
timing4,
timing5,
timing6,
timing7,
tokens1,
tokens2,
tokens3,
tokens4,
tokens5,
tokens6,
tokens7,
],
)
if __name__ == "__main__":
demo.launch(server_name="0.0.0.0")
|