配置
硬件
i7-11700@2.50GHz
64GB RAM
RTX 3060
软件
1 pip install torch torchvision trochaudio --index-url https://download.pytorch.org/whl/cu128
模型
本地部署使用,每个模型使用独立的虚拟环境运行。
1 2 python -m venv venv .\venv\Scripts\activate
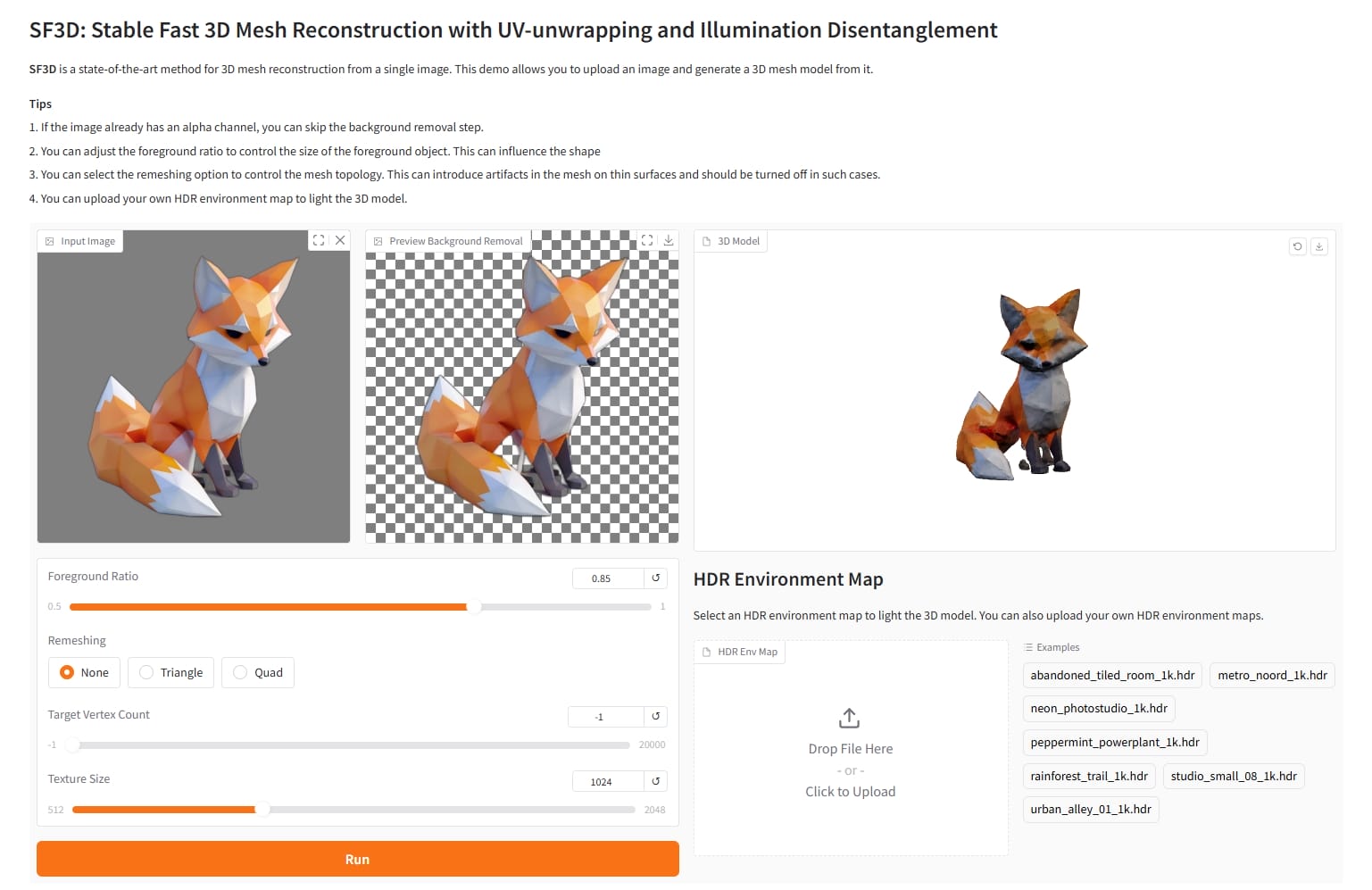
SF3D
1 2 3 git clone https://github.com/Stability-AI/stable-fast-3d.git cd stable-fast-3d
依赖安装报错,把 requirement.txt 里的 texture_baker 和 uv_unwrapper 删除,手动安装
1 2 3 4 5 6 7 8 9 10 11 12 cd texture_bakerpython setup.py install cd ../uv_unwrapperpython setup.py install cd ..pip install -r requirements.txt pip install -r requirements-demo.txt pip install -U gradio gradio_client python gradio_app.py
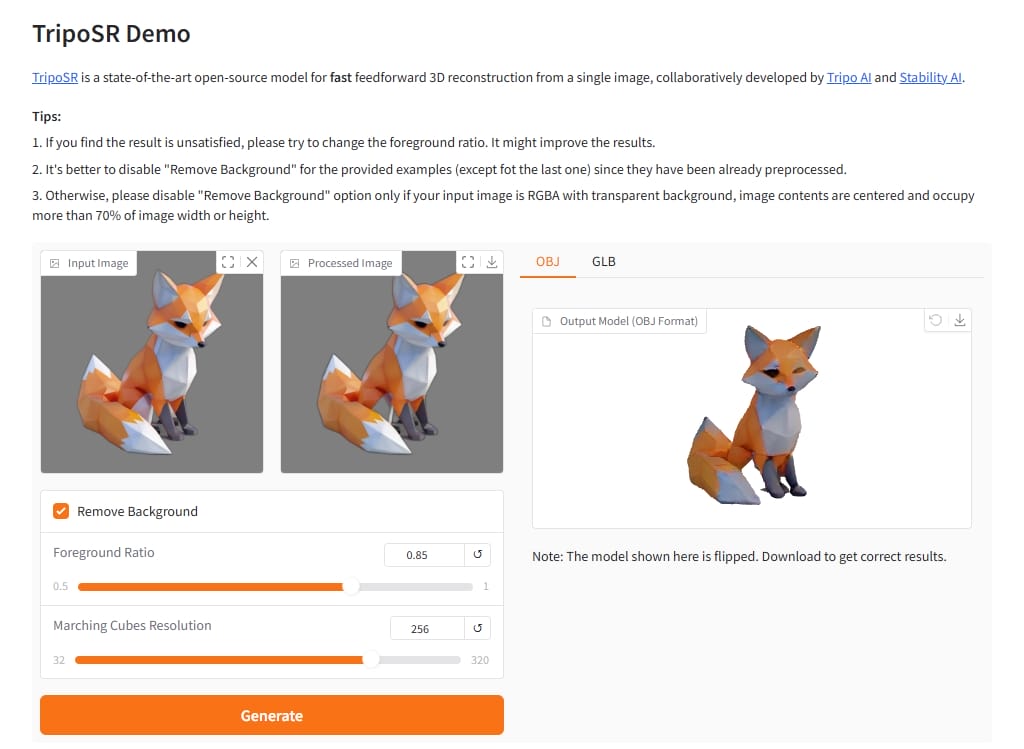
TripoSR
1 2 3 4 5 6 7 8 9 10 11 git clone https://github.com/VAST-AI-Research/TripoSR.git cd TripoSRpip install -r requirements.txt pip install onnxruntime pip install -U gradio transformers tokenizers python gradio_app.py --listen
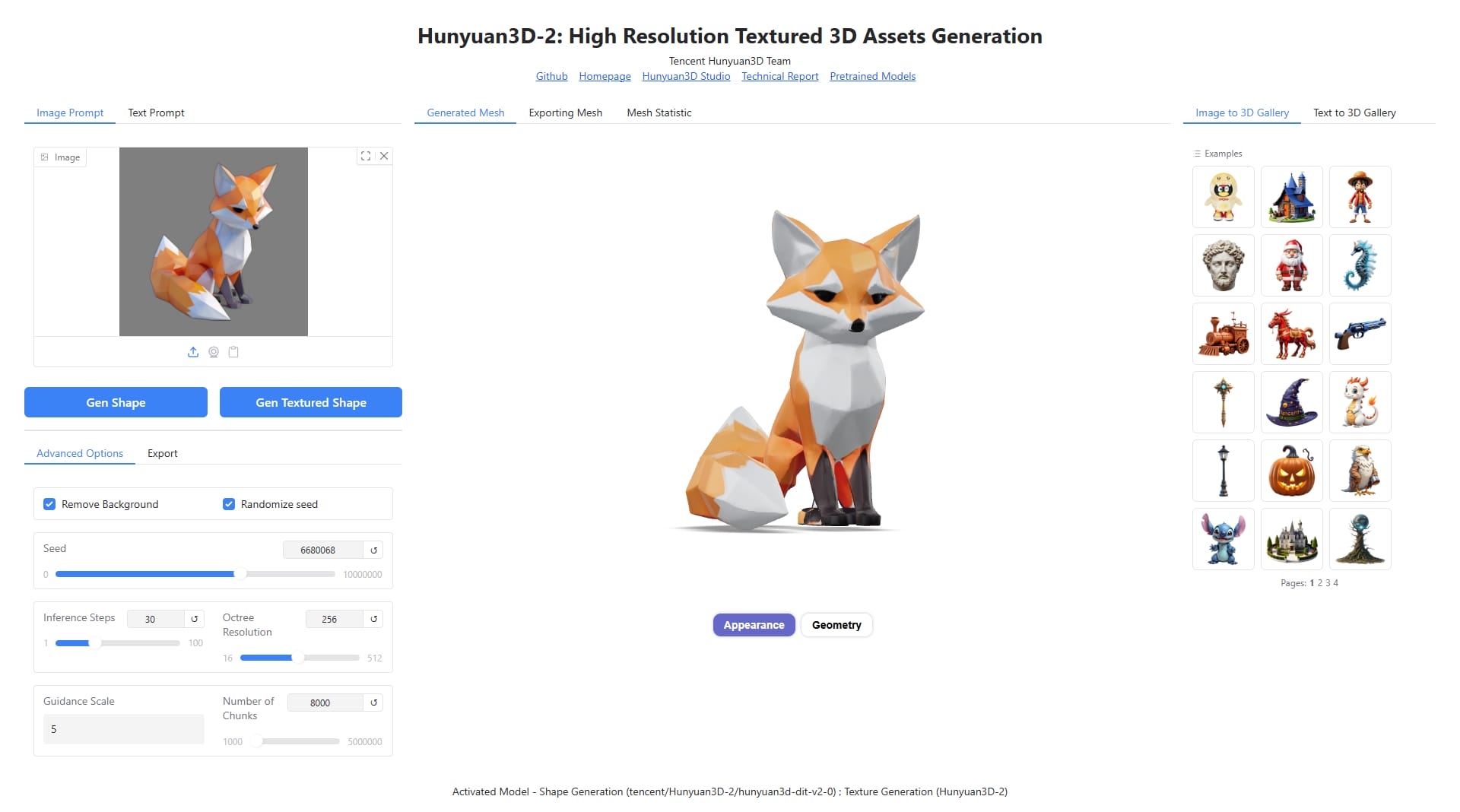
Hunyuan3D-2.0
1 2 3 4 5 6 7 8 9 10 11 git clone https://github.com/Tencent-Hunyuan/Hunyuan3D-2.git cd Hunyuan3D-2pip install -r requirements.txt pip install -e . cd hy3dgen/texgen/custom_rasterizerpython setup.py install cd ../differentiable_rendererpython setup.py install
直接运行的话路由有问题,需修改 gradio_app.py
1 app = gr.mount_gradio_app(app, demo, path="" )
运行
1 2 python gradio_app.py --model_path tencent/Hunyuan3D-2 --subfolder hunyuan3d-dit-v2-0 --texgen_model_path tencent/Hunyuan3D-2 --low_vram_mode
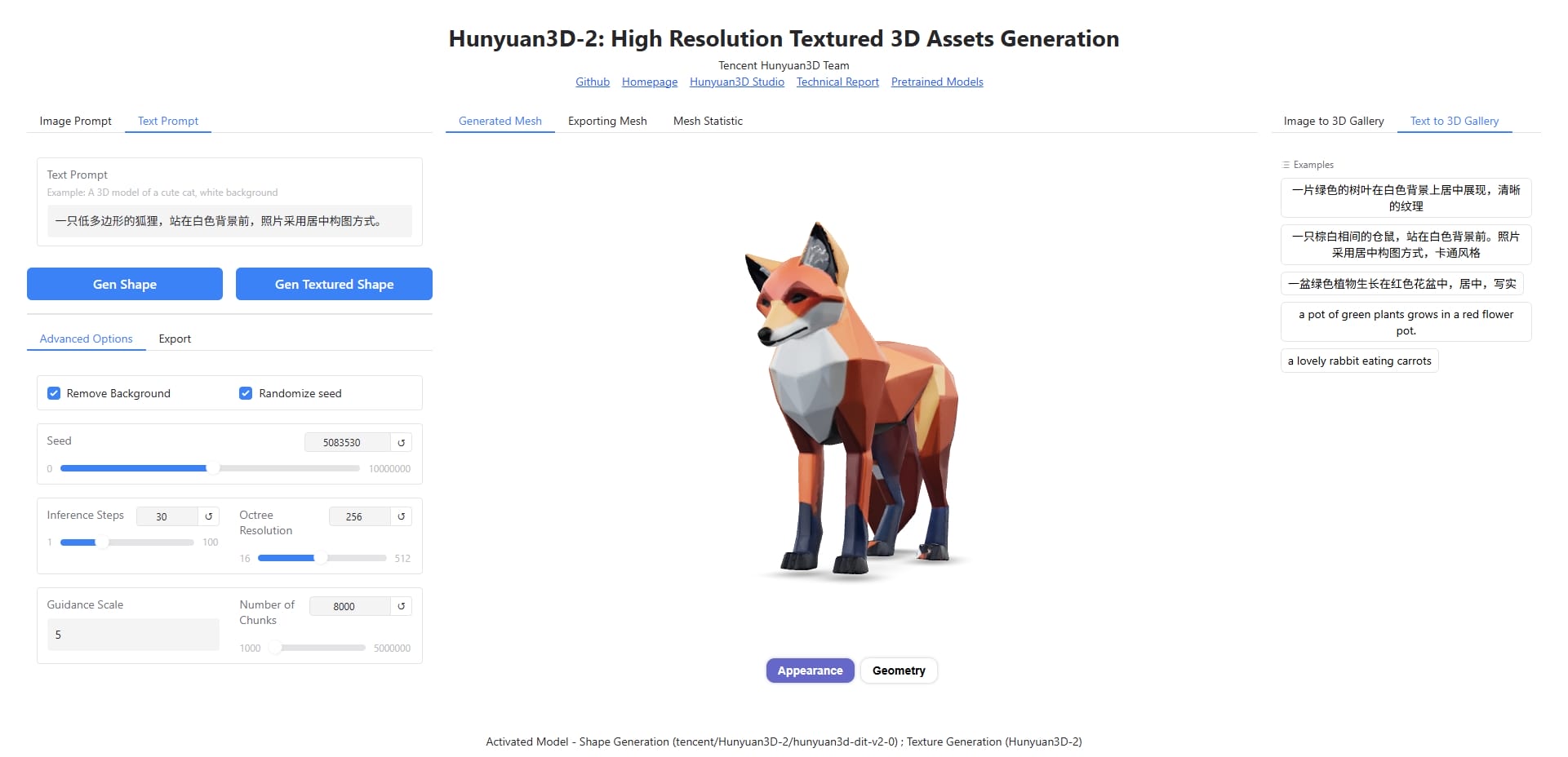
启用 text-to-3d 需要加个 patch,在项目根目录新建 fix_lazy_loading.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import sysimport importlibdef patch_t5_tokenizer (): """Force proper loading of T5 tokenizer""" try : import transformers.models.t5.tokenization_t5 if hasattr (transformers.models.t5.tokenization_t5, 'T5Tokenizer' ): print ("T5Tokenizer successfully loaded" ) return True else : print ("T5Tokenizer not found in module" ) return False except Exception as e: print (f"Failed to patch T5 tokenizer: {e} " ) return False def patch_transformers (): """Apply patches to fix lazy loading""" import transformers from transformers import T5Tokenizer, T5TokenizerFast import transformers.models.t5.tokenization_t5 as t5_tokenizer_module if not hasattr (t5_tokenizer_module, 'T5Tokenizer' ): t5_tokenizer_module.T5Tokenizer = T5Tokenizer print ("Transformers patching complete" ) if __name__ == "__main__" : patch_transformers() patch_t5_tokenizer()
更新 gradio_app.py,导入 patch 文件
1 2 3 import loggerimport fix_lazy_loadingfix_lazy_loading.patch_transformers()
启用 text-to-3d 需要在运行时添加命令行参数 --enable_t23d
1 2 3 4 5 pip install sentencepiece python gradio_app.py --model_path tencent/Hunyuan3D-2 --subfolder hunyuan3d-dit-v2-0 --texgen_model_path tencent/Hunyuan3D-2 --low_vram_mode --enable_t23d
文本转模型相当慢,预计 40min 左右😂
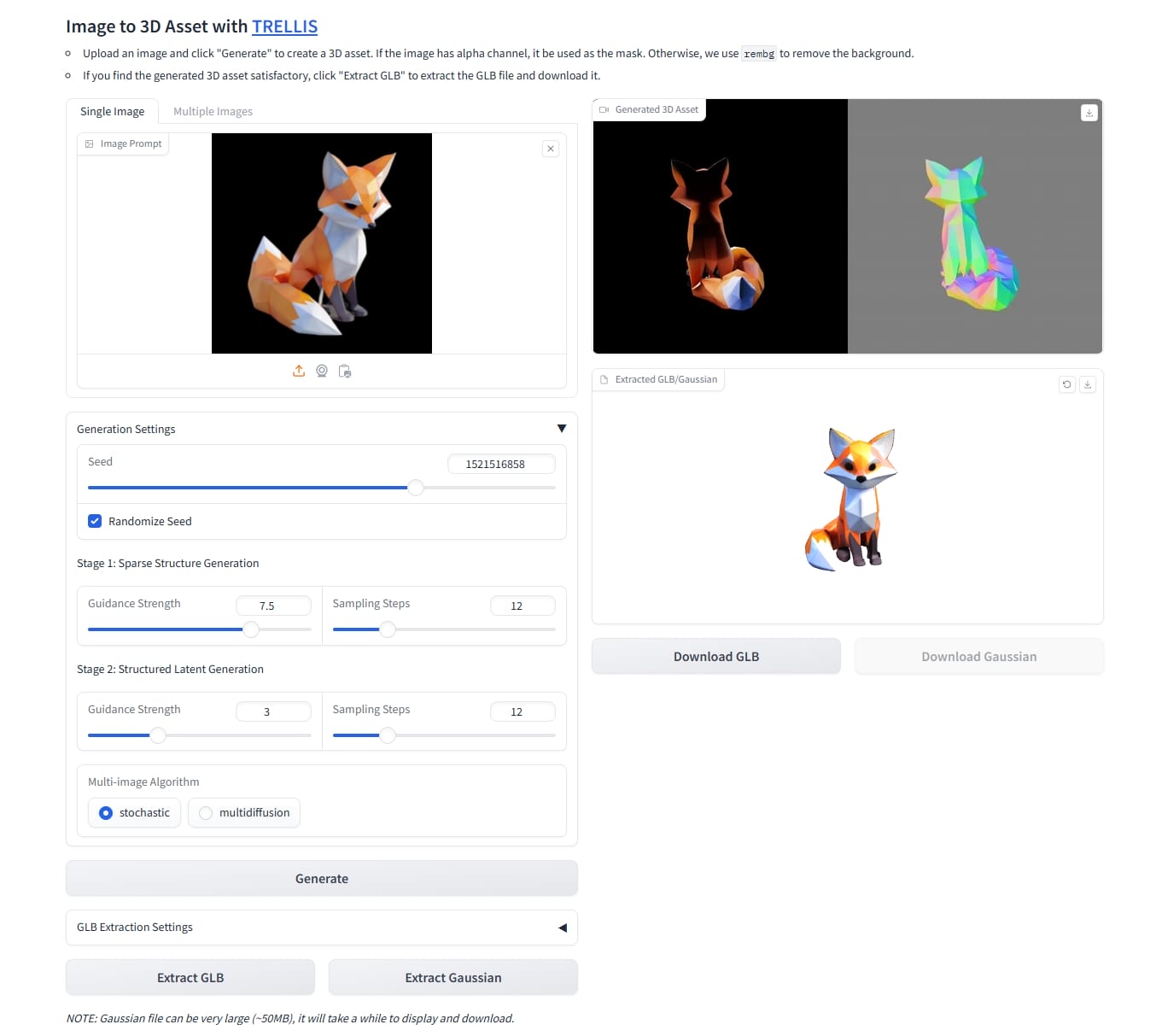
TRELLIS
Windows 上直接跑各种问题(Setting Up Trellis on Windows #3 ),后面直接找了个现成的 IgorAherne/trellis-stable-projectorz installer,暂不支持 text-to-3d
修改 code/gradio_main.py ,绑定到 0.0.0.0
1 demo.launch(server_name="0.0.0.0" )
解压后双击运行 run-gradio-fp16.bat,会自动创建虚拟环境。如果需要登录 huggingface 的话进入虚拟环境操作即可。
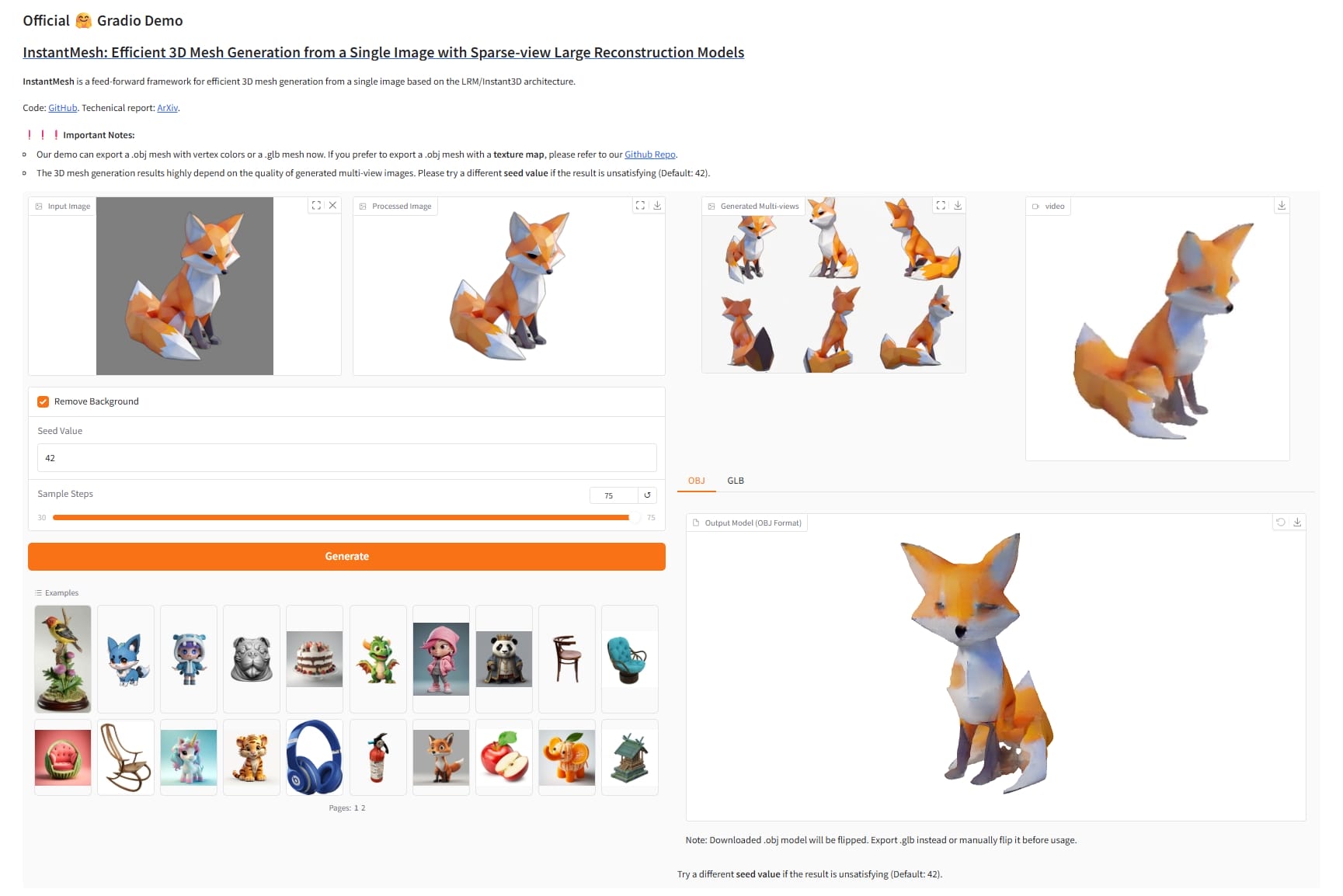
InstantMesh
1 2 3 4 5 6 7 8 9 10 11 git clone https://github.com/TencentARC/InstantMesh.git cd InstantMeshpip install Ninja onnxruntime pip install -r requirements.txt pip install -U gradio tokenizers transformers diffusers python app.py
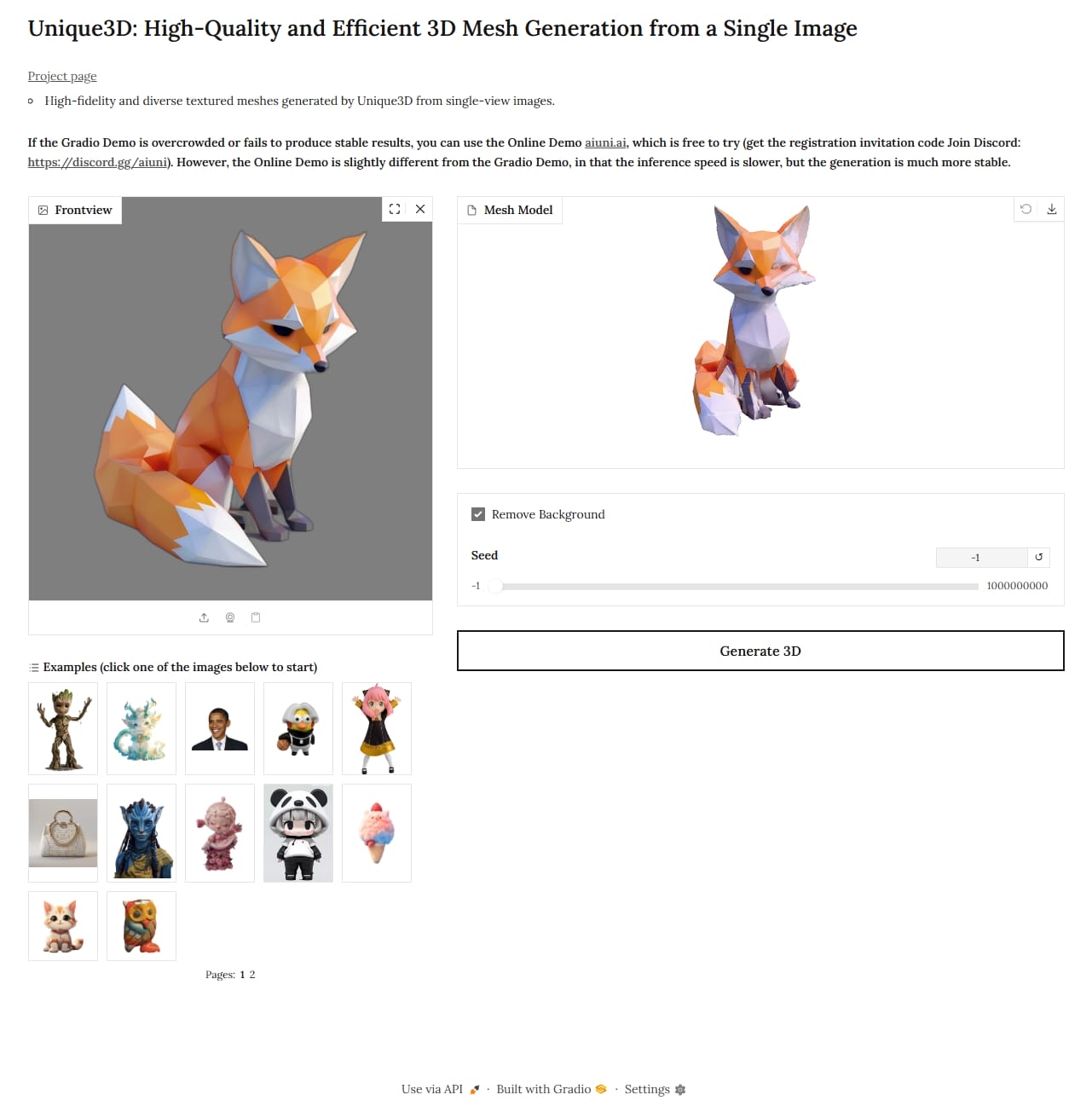
Unique3D
cuDNN 9.12.0:https://developer.nvidia.com/cudnn-downloads
TensorRT 10.13.2 GA: https://developer.nvidia.com/tensorrt/download/10x
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 git clone https://github.com/AiuniAI/Unique3D.git cd Unique3Dhttps://huggingface.co/spaces/Wuvin/Unique3D/tree/main pip install torch torchvision torchaudio xformers --index-url https://download.pytorch.org/whl/cu128 pip install torch-scatter -f https://data.pyg.org/whl/torch-2.8.0+cu128.html pip install onnxruntime-gpu --extra-index-url https://pypi.ngc.nvidia.com pip install diffusers==0.27.2 huggingface_hub==0.34.4 opencv-python-headless==4.8.1.78 pip install ninja rembg peft gradio datasets accelerate pip install wandb omegaconf transformers huggingface_hub[hf_xet] hf_xet pip install pygltflib trimesh typeguard fire jaxtyping pymeshlab "triton-windows<3.5" git clone https://github.com/facebookresearch/pytorch3d.git cd pytorch3dpython setup.py install cd ..git clone https://github.com/NVlabs/nvdiffrast.git cd nvdiffrastpip install . cd ..python app/gradio_local.py --listen --port 7860
修改 ./app/gradio_local.py 添加调用参数 allowed_paths,创建并添加临时目录(运行的磁盘,可能需要手动创建)
1 2 3 4 5 6 7 demo.queue(default_concurrency_limit=1 ).launch( server_port=None if port == 0 else port, share=share, root_path=gradio_root if gradio_root != "" else None , allowed_paths=["D:/tmp/gradio" ], **launch_args, )
报错:ImportError: cannot import name 'cached_download' from 'huggingface_hub'
在 .\venv\Lib\site-packages\diffusers\utils\dynamic_modules_utils.py 的 import 中删除 cached_download 导入
报错:显存不足(暂时没管)
1 2 3 4 5 2025-09-05 11:40:44.0622507 [E:onnxruntime:Default, tensorrt_execution_provider.h:89 onnxruntime::TensorrtLogger::log ] [2025-09-05 03:40:44 ERROR] [virtualMemoryBuffer.cpp::nvinfer1::StdVirtualMemoryBufferImpl::resizePhysical::141] Error Code 1: Cuda Driver (In nvinfer1::StdVirtualMemoryBufferImpl::resizePhysical at optimizer/builder/virtualMemoryBuffer.cpp:141) 2025-09-05 11:40:44.0821153 [E:onnxruntime:Default, tensorrt_execution_provider.h:89 onnxruntime::TensorrtLogger::log ] [2025-09-05 03:40:44 ERROR] [globWriter.cpp::nvinfer1::builder::HybridGlobWriter::HybridGlobWriter::494] Error Code 2: OutOfMemory (Requested size was 1024 bytes.) 2025-09-05 11:40:44.0911560 [E:onnxruntime:, sequential_executor.cc:572 onnxruntime::ExecuteKernel] Non-zero status code returned while running TRTKernel_graph_main_graph_15095719904311875781_0 node. Name:'TensorrtExecutionProvider_TRTKernel_graph_main_graph_15095719904311875781_0_0' Status Message: TensorRT EP failed to create engine from network. EP Error: [ONNXRuntimeError] : 11 : EP_FAIL : Non-zero status code returned while running TRTKernel_graph_main_graph_15095719904311875781_0 node. Name:'TensorrtExecutionProvider_TRTKernel_graph_main_graph_15095719904311875781_0_0' Status Message: TensorRT EP failed to create engine from network. using ['TensorrtExecutionProvider' , 'CUDAExecutionProvider' , 'CPUExecutionProvider' ] Falling back to ['CPUExecutionProvider' ] and retrying.
requirements.txt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 accelerate==1.10.1 aiofiles==23.2.1 aiohappyeyeballs==2.6.1 aiohttp==3.12.15 aiosignal==1.4.0 altair==5.5.0 annotated-types==0.7.0 antlr4-python3-runtime==4.9.3 anyio==4.10.0 attrs==25.3.0 Brotli==1.1.0 certifi==2025.8.3 charset-normalizer==3.4.3 click==8.2.1 colorama==0.4.6 coloredlogs==15.0.1 contourpy==1.3.3 cycler==0.12.1 dataclasses-json==0.6.7 datasets==4.0.0 Deprecated==1.2.18 diffusers==0.27.2 dill==0.3.8 fastapi==0.116.1 ffmpy==0.6.1 filelock==3.13.1 fire==0.7.1 flatbuffers==25.2.10 fonttools==4.59.2 frozenlist==1.7.0 fsspec==2024.2.0 gitdb==4.0.12 GitPython==3.1.45 gradio==5.44.1 gradio_client==1.12.1 groovy==0.1.2 h11==0.16.0 hf-xet==1.1.9 httpcore==1.0.9 httpx==0.28.1 huggingface-hub==0.34.4 humanfriendly==10.0 idna==3.10 imageio==2.37.0 importlib_metadata==8.7.0 importlib_resources==6.5.2 iopath==0.1.10 jaxtyping==0.3.2 Jinja2==3.1.4 jsonschema==4.25.1 jsonschema-specifications==2025.4.1 kiwisolver==1.4.9 lazy_loader==0.4 llvmlite==0.44.0 markdown-it-py==4.0.0 MarkupSafe==2.1.5 marshmallow==3.26.1 matplotlib==3.10.6 mdurl==0.1.2 mpmath==1.3.0 msvc_runtime==14.44.35112 multidict==6.6.4 multiprocess==0.70.16 mypy_extensions==1.1.0 narwhals==2.3.0 networkx==3.3 ninja==1.13.0 numba==0.61.2 numpy==1.26.4 nvdiffrast @ file:///D:/workplace/Unique3D/nvdiffrast omegaconf==2.3.0 onnxruntime-gpu==1.22.0 opencv-python-headless==4.8.1.78 orjson==3.11.3 ort-nightly-gpu==1.15.0.dev20230502003 packaging==25.0 pandas==2.3.2 peft==0.17.1 pillow==10.4.0 platformdirs==4.4.0 pooch==1.8.2 portalocker==3.2.0 propcache==0.3.2 protobuf==6.32.0 psutil==7.0.0 pyarrow==21.0.0 pyarrow-hotfix==0.7 pydantic==2.6.1 pydantic_core==2.16.2 pydub==0.25.1 pygltflib==1.16.5 Pygments==2.19.2 PyMatting==1.1.14 pymeshlab==2025.7 pyparsing==3.2.3 pyreadline3==3.5.4 python-dateutil==2.9.0.post0 python-multipart==0.0.20 pytorch3d==0.7.8 pytz==2025.2 pywin32==311 PyYAML==6.0.2 referencing==0.36.2 regex==2025.9.1 rembg==2.0.67 requests==2.32.5 rich==14.1.0 rpds-py==0.27.1 ruff==0.12.11 safehttpx==0.1.6 safetensors==0.6.2 scikit-image==0.25.2 scipy==1.16.1 semantic-version==2.10.0 sentry-sdk==2.36.0 shellingham==1.5.4 six==1.17.0 smmap==5.0.2 sniffio==1.3.1 starlette==0.47.3 sympy==1.13.3 tensorrt @ file:///C:/Program%20Files/NVIDIA/TensorRT-10.13.2.6/python/tensorrt-10.13.2.6-cp311-none-win_amd64.whl#sha256=bed88a7ce09338faf6a48f82954b20d8993189a2a4ce2d4401899fdcf859931a termcolor==3.1.0 tifffile==2025.8.28 tokenizers==0.22.0 tomlkit==0.12.0 torch==2.8.0+cu128 torch_scatter==2.1.2+pt28cu128 torchvision==0.23.0+cu128 tqdm==4.67.1 transformers==4.56.1 trimesh==4.8.1 triton-windows==3.4.0.post20 typeguard==4.4.4 typer==0.17.3 typing-inspect==0.9.0 typing-inspection==0.4.1 typing_extensions==4.15.0 tzdata==2025.2 urllib3==2.5.0 uvicorn==0.35.0 wandb==0.21.3 websockets==11.0.3 wrapt==1.17.3 xformers==0.0.32.post2 xxhash==3.5.0 yarl==1.20.1 zipp==3.23.0
Stable-Zero123
需要通过 threestudio 使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 git clone https://huggingface.co/stabilityai/stable-zero123 git clone https://github.com/threestudio-project/threestudio.git cp stable-zero123/stable_zero123.ckpt threestudio/load/zero123/cd threestudiopip install ninja pip install -r requirements.txt pip install nerfacc==0.5.2 envlight pip install libigl==2.5.1 pip install huggingface_hub==0.25.* git clone https://github.com/NVlabs/nvdiffrast.git cd nvdiffrastpip install . python -m pip install pip==23.0.1 pip install git+https://github.com/NVlabs/tiny-cuda-nn/
添加环境变量
1 D:\Program Files\Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.44.35207\bin\Hostx64\x64
直接跑预估 68h,trainer.max_steps 配置为 600,改成 5 只需要半小时
1 python launch.py --config configs/stable-zero123.yaml --train --gpu 0 trainer.max_steps=5 data.image_path=./load/images/hamburger_rgba.png
但是导出模型报错,暂未解决(太难用了)
1 python launch.py --config "outputs/zero123-sai/[64, 128, 256]_hamburger_rgba.png@20250901-142614/configs/parsed.yaml" --export --gpu 0 resume="outputs/zero123-sai/[64, 128, 256]_hamburger_rgba.png@20250901-142614/ckpts/last.ckpt" system.exporter_type=mesh-exporter
参阅